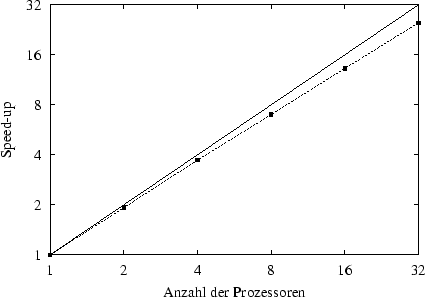
Die Beschleunigung der parallelen Berechnung gegenüber der sequentiellen Berechnung ist in Abbildung 7.18 in einem Speed-up-Diagramm dargestellt. Die hierfür notwendigen Zeitmessungen wurden auf einem Linux-Cluster mit Pentium-II Prozessoren mit 350 MHz Taktfrequenz und 128 MB Speicher pro Prozessor durchgeführt. Verwendet wurde ein 100 MBit Netzwerk mit einem Switch als Verteiler.
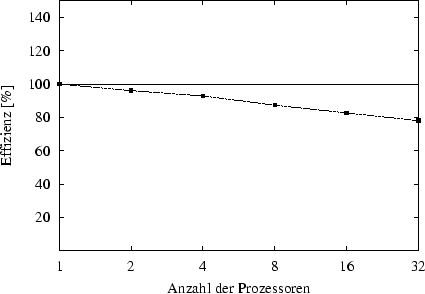
Das in Abbildung 7.19 dargestellte Effizienz-Diagramm zeigt deutlich die gute Effizienz der Parallelisierung. Für Prozessoranzahlen von bis zu vier Prozessoren, bei denen die Elementanzahlen auf den Prozessoren nur gering vom Durchschnitt abweichen, wird eine Effizienz von jeweils über 90 Prozent erreicht. Der schlechtere Lastausgleich und der höhere sequentielle Aufwand bei höheren Prozessoranzahlen spiegeln sich auch im Effizienz- und Speed-up-Diagramm wieder. So liegt die Effizienz bei 16 Prozessoren nur bei 82,7 % und bei der Berechnung mit 32 Prozessoren wird die Rechenleistung von 24,9 Prozessoren erreicht, was einer Effizienz von 78,1 % entspricht.